Latest Issue
Environmental Variables Determining Soil Physical Properties and Carbon Content at the Catchment Scale, Stung Chrey Bak Observatory, Cambodia
Published: December 31,2025The Negative Experiences of Low-Income Citizen Commute and Their Intentions Toward Public Bus in Phnom Penh
Published: December 31,2025Reliability Study on the Placement of Electric Vehicle Charging Stations in the Distribution Network of Cambodia
Published: December 31,2025Planning For Medium Voltage Distribution Systems Considering Economic And Reliability Aspects
Published: December 31,2025Security Management of Reputation Records in the Self-Sovereign Identity Network for the Trust Enhancement
Published: December 31,2025Effect of Enzyme on Physicochemical and Sensory Characteristics of Black Soy Sauce
Published: December 31,2025Activated Carbon Derived from Cassava Peels (Manihot esculenta) for the Removal of Diclofenac
Published: December 31,2025Land Use and Land Cover Distribution across Litho-Mineral Alteration of an Irrigated Catchment of the Tonle Sap Lake, Cambodia
Published: December 31,2025Impact of Smoking Materials on Smoked Fish Quality and Polycyclic Aromatic Hydrocarbon Contamination
Published: December 31,2025Estimation of rainfall and flooding with remotely-sensed spectral indices in the Mekong Delta region
Published: December 31,2025Word Spotting on Khmer Palm Leaf Manuscript Documents
-
1. Department of Information and Communication Engineering, Institute of Technology of Cambodia, Russian Federation Blvd., P.O. Box 86, Phnom Penh, Cambodia
Academic Editor:
Received: July 17,2023 / Revised: / Accepted: August 07,2023 / Available online: June 30,2024


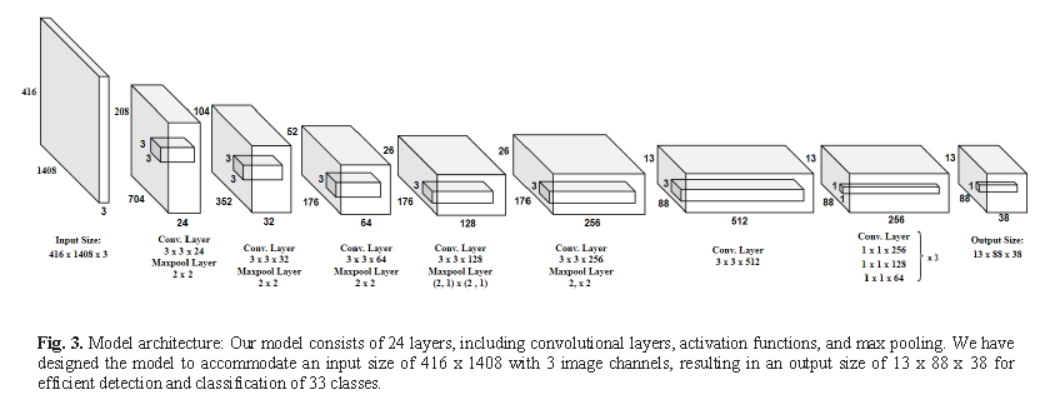

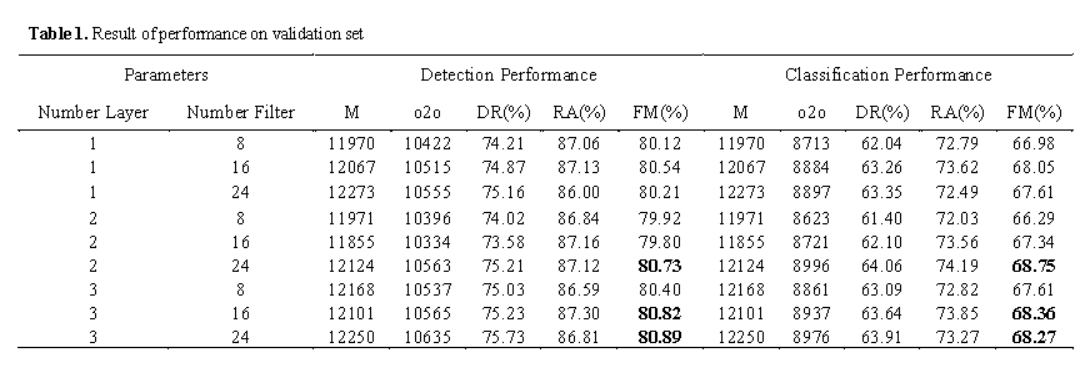

Word spotting plays a crucial role in document analysis, particularly for ancient palm leaf manuscripts. Khmer palm leaf manuscripts, which are written on rectangularly cut and dried palm leaf sheets, hold significant cultural value in Cambodia. These manuscripts contain valuable historical, religious, and linguistic information, making their preservation essential. However, extracting information from them is challenging due to their fragility, age, and the complexity of Khmer writing and word formation. This study focuses on word spotting and investigates the construction of a Region Proposal Network (RPN) using the You Only Look Once (YOLO) technique and Convolutional Neural Network (CNN) for the accurate and efficient identification of specific words or phrases within the documents. The proposed method is evaluated using the SleukRith dataset, which consists of 1,971 images of Khmer palm leaf manuscripts. Among these, 1,379 images are allocated to the training set, 395 to the test set, and approximately 197 to the validation set. Parameter tuning is conducted on two variables: the number of layers and the number of filters. The results demonstrate that the optimal model comprises 3 layers and 24 filters, with a threshold of 0.4. The achieved detection performance accuracy is approximately 80.86%, while the classification performance reaches 69.29% for the 33 classes of Khmer characters.