Latest Issue
Design Of Buck Converter For Low Power Application A Comparative Study For Selecting The Semiconductor Devices
Published: April 30,2026Determination of Mechanical Properties of Cambodian Sandstone using the Brazilian Test and the Semi Circular Bending Test
Published: April 30,2026Quality Evaluation of Cambodian Rice Seeds Under Organic Tillage and Green Manure Production Systems
Published: April 30,2026Assessing the Impact of Motorcycle Emissions on Urban Air Quality: A Case Study at the Institute of Technology of Cambodia
Published: April 30,2026Characterization of Antimicrobial Resistance Profiles and Extended-Spectrum Beta-Lactamase Resistance Genes in Salmonella Isolates from Different Food Matrices in Cambodia
Published: April 30,2026Impact of rice agro-system on aroma accumulation of Phka Rumdoul rice variety in Cambodia
Published: April 30,2026Evaluation of The Susceptibility of Rice Germplasms In Cambodia To The Rice Root-Knot Nematode, Meloidogyne Graminicola
Published: April 30,2026Correlation Between Dynamic Cone Penetrometer (DCP) and California Bearing Ratio (CBR) for Subgrade Soil Material in Cambodia
Published: April 30,2026Effect of Storage Conditions on the Stability of Rice Fragrance and Protein Content in Phka Rumdoul Rice Variety
Published: April 30,2026Assessment of Hydraulic Transport of Pesticides at the Watershed: Case study Tonle Sap and Mekong River
Published: April 30,2026Word Spotting on Khmer Palm Leaf Manuscript Documents
-
1. Department of Information and Communication Engineering, Institute of Technology of Cambodia, Russian Federation Blvd., P.O. Box 86, Phnom Penh, Cambodia
Academic Editor:
Received: July 17,2023 / Revised: / Accepted: August 07,2023 / Available online: June 30,2024


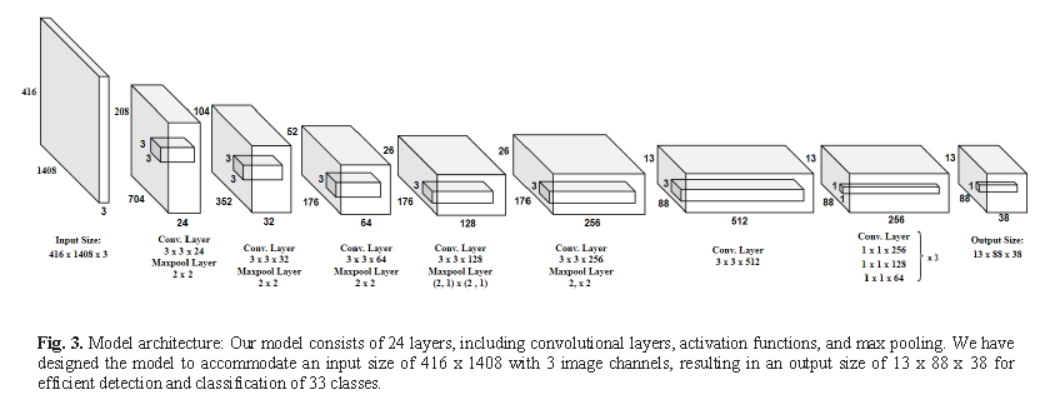

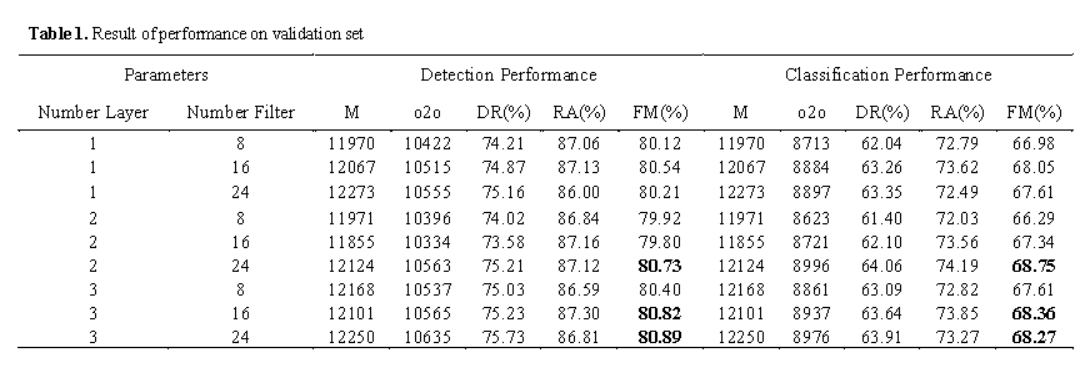

Word spotting plays a crucial role in document analysis, particularly for ancient palm leaf manuscripts. Khmer palm leaf manuscripts, which are written on rectangularly cut and dried palm leaf sheets, hold significant cultural value in Cambodia. These manuscripts contain valuable historical, religious, and linguistic information, making their preservation essential. However, extracting information from them is challenging due to their fragility, age, and the complexity of Khmer writing and word formation. This study focuses on word spotting and investigates the construction of a Region Proposal Network (RPN) using the You Only Look Once (YOLO) technique and Convolutional Neural Network (CNN) for the accurate and efficient identification of specific words or phrases within the documents. The proposed method is evaluated using the SleukRith dataset, which consists of 1,971 images of Khmer palm leaf manuscripts. Among these, 1,379 images are allocated to the training set, 395 to the test set, and approximately 197 to the validation set. Parameter tuning is conducted on two variables: the number of layers and the number of filters. The results demonstrate that the optimal model comprises 3 layers and 24 filters, with a threshold of 0.4. The achieved detection performance accuracy is approximately 80.86%, while the classification performance reaches 69.29% for the 33 classes of Khmer characters.